강의 주소
https://opentutorials.org/course/3161
MySQL - 생활코딩
수업소개 무료이면서, 오픈소스이고, 3대 데이터베이스 중에 하나인 MySQL의 입문 수업입니다. 수업대상 정보기술의 심장인 데이터베이스가 어떻게 동작하는지 궁금하신 분 데이터를 보다 전
opentutorials.org
1강. 수업소개
관계형 데이터베이스 이용: 데이터를 표의 형태로 정리정돈 / 정렬, 검색과 같은 작업 빠르고 편리하고 안전하게 할 수 있음.
관계형 데이터베이스라는 이론적 토대 위에 만들어진 기술들, 아래 중 하나를 배우면 나머지 사용법도 알게 됨.

MySQL: 무료, 오픈소스, 관계형데이터베이스의 기능을 대부분갖춤 / WEB사이트를 만들며 몇천이 넘는 데이터베이스를 사용할 수는X, WEB개발자들이 많이 사용, MySQL은 WEB과 함께 폭발적으로 동반 성장
2강. 데이터베이스의 목적
스프레트시트와 달리 프로그래밍 언어를 통해서 제어 / 데이터베이스를 이용해 데이터베이스에 저장된 데이터를 웹, 앱을 통해서 사람들에게 공유할 수 있음. 또 데이터를 빅데이터나 인공지능을 이용해서 분석할 수 있음.
3강. MySQL 설치
설치방법
강의와 다른 방식으로 진행하였다. 아래 사이트들을 참고하여 설치하였다.
MySQL 다운로드 및 설치하기(MySQL Community 8.0)
SQL을 본격적으로 사용하려면 DBMS를 설치해야 합니다. 여러 가지 DBMS 중에서 MySQL 설치 하는 방법을 알아보고, 정상적으로 설치가 되었는지 확인하는 방법을 알아보겠습니다. 2021년 10월 기준 MySQL
hongong.hanbit.co.kr
https://velog.io/@ljs923/MySQL-MySQL-%EB%8B%A4%EC%9A%B4-%EB%B0%8F-%EC%84%A4%EC%B9%98Windows
[MySQL] MySQL 다운 및 설치(Windows 환경)
MySQL 설치 주소https://www.mysql.com/downloads/원하는 Setup Type 설정Check Requirements 단계에서 Next -> Yes 선택Installation 단계에서 설치 목록 확인 -> Execute설치 완료가 되면
velog.io
MySQL 완전 삭제 후 재설치하기
MySQL 설치 시에 예전에 사용했던 것들이 남아있으면 새로 설치하는 버전에 문제가 될 수 있다. 그래서 미리 다 삭제하고 설치하여야 한다. 다음과 같은 순서로 진행하면 된다.(Installer가 없다면
velog.io
MySQL 설치 중 발생하는 3306 포트 충돌 문제 해결 방법 3가지
MySQL을 설치하려고 할 때, "3306 포트를 사용할 수 없다"는 에러때문에 설치를 못하고 있나요? 3306 포트는 MySQL의 기본 통신 포트로, 이미 시스템 상에서 다른 프로세스나 애플리케이션이 이 포트를
devit.koreacreatorfesta.com
설치 완료 후
※workbench를 사용하지 않음.
1. 시작프로그램에서 cmd 입력 후 명령프롬프트 접속.
2. cd 명령으로 mysql이 있는 bin 폴더로 이동
(나의 경우 아래와 같이 입력)
cd C:\Program Files\MySQL\MySQL Server 8.0\bin
3. mysql -uroot -p 입력 후 비밀번호 입력
4강. MySQL의 구조
연관된 데이터(표)들을 그룹핑할때 사용하는 일종의 폴더 => 데이터베이스 (스키마)
데이터베이스(스키마)들은 데이터베이스 서버에 저장됨.
우리가 MySQL을 설치한 것은 데이터베이스서버를 설치한 것임. 그 프로그램이 갖고 있는 기능성을 이용해서 데이터와 관련된 여러 작업을 하는 것.
5강. 서버접속
데이터베이스 통해 얻을 수 있는 효용 - 자체적인 보안 체계, 권한 기능
-u 뒤에 접속할 바로 사용자를 붙임.
root(루트) : 기본 유저 / 관리자(모든 권한이 열려있음.) / 실제로 root의 권한으로 데이터베이스를 직접다루는것을 위험함. 중요시스템의 경우 별도의 사용자 만들어 평소에 작업을 하다가 중요한 작업이 있을 때만 root로 들어가는 것이 권장됨.
-p뒤에 바로 비밀번호를 입력해도 되지만 비밀번호가 노출이 되므로 -p까지만 입력하고 다음줄에 비밀번호가 무엇인지 물어보면 비밀번호를 입력
mysql -uroot -p
(4강의 MySQL의 구조 그림에서 우리는 데이터베이스 서버에 들어온 것임.)
6강. 스키마의 사용
검색창에 mysql create database 입력
검색창에 mysql delete database 입력
검색창에 how to show database list in mysql 입력
데이터베이스 생성 명령 : CREATE DATABASE 데이터베이스명;
데이터베이스 삭제 명령 : DROP DATABASE 데이터베이스명;
데이터베이스 목록 확인 명령 : SHOW DATABASES;
1. 데이터베이스 생성
CREATE DATABASE opentutorials;
2. 데이터베이스 리스트 확인
SHOW DATABASES;
3. 어떤 데이터베이스 사용할지 선택하기 (USE 데이터베이스명;)
USE opentutorials;이제 MySQL은 지금부터 내리는 명령을 opentutorials라는 스키마에 있는 표를 대상으로 명령을 실행하게 됨.
(4강의 SQL의 구조에서 데이터베이스를 생성하는 것까지 하였고 표를 만질 수 있는 준비가 끝남.)
7강. SQL과 테이블의 구조
SQL
Structured - 표를 작성하는 것, 정리정돈 하는 것, 구조화되어 있는 것
Query - 수정, 삭제 등 데이터베이스에게 요청(질의)함
Language - 공통의 약속에 따라 데이터베이스 서버에 요청
특징1. 매우 쉽다.
특징2. 중요함. 관계형 데이터베이스라는 카테고리에 속하는 제품들이 공통적으로 데이터베이스 서버를 제어할 때 사용, 표준화도 되어 있음.
=> 가성비 좋다
용어정리
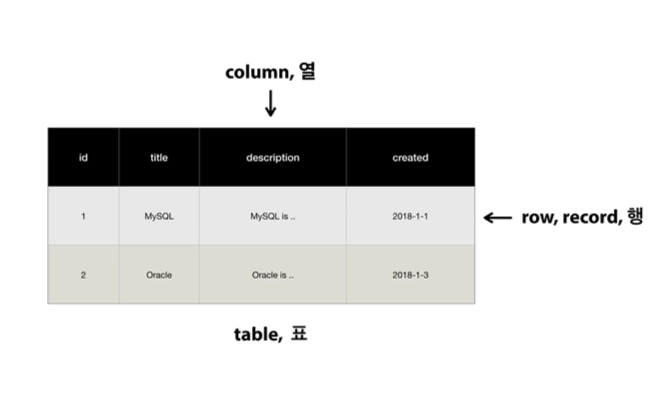
1. 표, table
2. (x축 방향, 수평) row(로우), record(레코드), 행 / 데이터 하나하나
3. (y축 방향, 수직) colum(컬럼), 열 / 보통 데이터베이스에서 컬럼을 이야기 할 때에는 데이터의 타입이라고 생각하면 됨. / 데이터의 구조
아래의 표에서는 2개의 행이 있음. (데이터가 2건이 있다는 뜻.) 그리고 4개의 컬럼이 있음.
8강. 테이블의 생성
검색 : create tabel in mysql / create table in mysql cheat sheet(치트 시트)
;(세미콜론)을 붙이지 않고 엔터를 누르면 줄바꿈이 됨.
테이블 생성 형식
CREATE TABLE 테이블명(
컬럼명 데이터타입(길이) ... ,
컬럼명 데이터 타입(길이) ... ,
...
PRIMARY KEY(...)
)(위의 형식은 가독성이 좋게 일부러 다음줄에 넘겨서 띄워서 씀. 실제 cmd에서는 ;(세미콜론)을 붙이지 않고 엔터를 누르면 줄바꿈이 됨. )
컬럼의 데이터 타입을 강제할 수 있음. 숫자를 입력하게끔 하고 싶으면 검색: mysql datatype / mysql dataype number ...
https://incodom.kr/DB_-_%EB%8D%B0%EC%9D%B4%ED%84%B0_%ED%83%80%EC%9E%85/MYSQL
생물정보 전문위키, 인코덤
Wikipedia for Bioinformatics
www.incodom.kr
만드려고 하는 테이블의 모습

데이터 타입 지정 : INT(m), VARCHAR(size), TEXT(size) ...
INT(m) : 숫자를 검색했을때 얼마까지만 노출시키는가(숫자를 얼마까지 저장할것인가에 대한 것은 X) / 보통 11을 많이 사용함.
NOT NULL: 값이 없는 것을 허용하지 않음 / 행을 입력할 때 반드시 내용을 쓰도록 하기
NULL : 값이 없는 것을 허용 / 값이 없는 채로 추가되고 나중에 내용을 입력하도록 하기
AUTO_INCREMENT : 자동으로 1씩 증가 (id컬럼이 중복되지 않는 식별자 갖게 하기)
DATETIME : 날짜와 시간을 모두 표현할 수 있음. (created는 생성된 시간을 나타내는 컬럼)
PRIMARY KEY(...) : 고유하고 중복되어서는 안되는 값 지정 (id 컬럼을 main 키 (주 키)가 되게끔 하)
CREATE TABLE topic(id INT(11) NOT NULL AUTO_INCREMENT, title VARCHAR(100) NOT NULL, description TEXT NULL,created DATETIME NOT NULL, author VARCHAR(30) NULL, profile VARCHAR(100) NULL, PRIMARY KEY(id));
(기본비밀번호 사용 시 에러 발생, 그럴 경우 에러메세지, 식별자가 있으므로 검색하여 해결할 것. 영상참조)
9강. CRUD
데이터베이스가 무엇이든 간에 막론하고 반드시 가지고 있는 4가지 작업
Create
Read
Update
Delete
이중에서도 중요한 것은 create와 read임. create와 read는 데이터베이스라면 반드시 가지고 있음. update와 delete는 없을 수도 있음. 어떤 분야에서는 수정과 삭제를 죄악시 함(역사, 회계)
10강. INSERT
데이터를 추가하는 것 - Create
검색: mysql create row
아래 명령으로 이전에 생성한 topic 테이블을 확인할 수 있음.
SHOW TABLES;
DESC describe의 약자, topic이라는 테이블의 구조를 볼 수 있음.
DESC topic;
topic이라는 테이블에 데이터를 추가할 것임. 행을 삽입하는 것이므로 INSERT INTO
id컬럼은 값을 지정하지 않으면 자동으로 AUTO_INCREMENT 됨. id를 따로 언급하지 않을 것.
VALUES에 있는 것이 어떤 컬럼인지는 앞에 대응되는 순서에 있는 것을 보고 알 수 있음. 즉, 순서가 같아야 함.
created 칼럼에는 날짜를 직접 적을 수 있음. NOW() 라고 하면 지금 현재시간이 됨.
INSERT INTO topic(title, description, created, author, profile) VALUES('MySQL', 'MySQL is ...', NOW(), 'egoing', 'developer');
추가한 데이터를 어떻게 볼 지(Read) 검색: how to read row in mysql
topic 테이블에서 데이터를 가져와서 선택, 특별한 언급이 없으면 모든 데이터를 가져옴. 중간에 * 표시
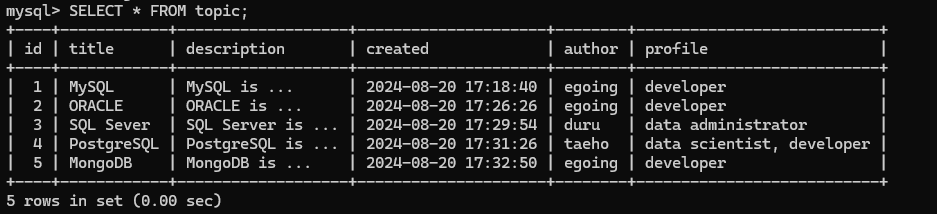
SELECT * FROM topic;
아래와 같이 데이터가 추가된 것을 볼 수 있음.

cmd 창에서 키보드 위/아래 화살표를 눌러 이전의 코드를 들고와서 수정하면 빠르게 row를 추가할 수 있음. 이렇게 다른 row도 추가함.
INSERT INTO topic(title, description, created, author, profile) VALUES('ORACLE', 'ORACLE is ...', NOW(), 'egoing', 'developer');INSERT INTO topic(title, description, created, author, profile) VALUES('SQL Sever', 'SQL Server is ...', NOW(), 'duru', 'data administrator');INSERT INTO topic(title, description, created, author, profile) VALUES('PostgreSQL', 'PostgreSQL is ...', NOW(), 'taeho', 'data scientist, developer');INSERT INTO topic(title, description, created, author, profile) VALUES('MongoDB', 'MongoDB is ...', NOW(), 'egoing', 'developer');
SELECT * FROM topic; 명령으로 5건의 데이터가 잘 들어갔음을 확인할 수 있음.

Create - INSERT문
Read - SELECT 문
Update
Delete
( INSERT와 SELECT문은 자주 사용되므로 알아둘 것 ! )
11강. SELECT
모든 데이터를 화면에 출력하고 싶을 때 아래와 같이 사용함. topic에 있는 모든 행를 출력함.
SELECT * FROM topic;
보고 싶은 칼럼만 출력하고 싶을 때 SELECT 와 FROM 사이에 원하는 칼람을 입력함.
SELECT id, title, author FROM topic;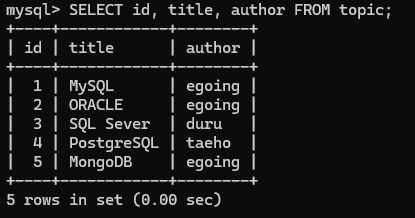
SELECT문 문법 검색 : mysql select syntax
공식문서에서 대괄호 부분( [ ] )은 생략가능하다는 뜻이고 '|' 로 구분되어 있으면 그 중 하나를 선택해서 쓰면 된다.
SELECT 뒤에는 컬럼의 목록이 나옴. FROM 은 생략이 가능함.
SELECT "egoing", 1+1;
WHERE문의 위치는 FROM 뒤에 있어야 함. WHERE문을 통해서 원하는 행, 필요한 행,정보만 볼 수 있음. 저자가 egoing인 행만을 보고 싶은 경우 아래와 같이 작성
SELECT id,title,created,author FROM topic WHERE author='egoing';
ORDER BY는 WHERE 뒤에 작성. ORDER BY 기준컬럼 정렬방식 [DESC | ACS]
DECS는 내림차순 정렬, ACS는 오름차순 정렬
SELECT id, title, created, author FROM topic WHERE author='egoing' ORDER BY id DESC;
데이터가 매우 많은 상태(ex) 10억건)에서 데이터를 제약없이 모두 가져오면 컴퓨터가 멈추게 됨.
맨 마지막에 LIMIT 숫자를 붙여 몇번째 행까지 볼지 제약해주면 됨.
SELECT id, title, created, author FROM topic WHERE author='egoing' ORDER BY id DESC LIMIT 2
데이터베이스를 잘한다 = SELECT문을 필요에 따라서 잘 사용한다.
12강. UPDATE
검색: mysql update
검색을 했을 때 목록 중 공식문서가 나옴. 대괄호( [ ] )가 쳐지지 않은 것은 필수로 입력해야 하는 것임. 공식문서의 설명 중 코드 아래부분에 있는 것은 어떻게 쓰면 될지 설명한 부분임. 앞의 SET assignment_list에서 assignment 설명부분을 보면 SET 뒤에는 컬럼명=값으로 입력하면 되고 assignment_list 설명부분을 보면 SET 뒤에는 컬럼명=값, 컬럼명=값 이런식으로 콤마(,)로 수정할 목록 여러개를 나열할 수 있다는 것을 알 수 있음.

UPDATE 테이블명 SET 컬럼명=수정한값, 컬럼명=수정한 값 WHERE 조건
WHERE 뒤에는 어느 행을 수정할 것인지 입력하면 됨.
아래의 코드에서는 WHERE id=2이므로 id가 2인 두번째 행의 description이 뒤의 값대로, title이 뒤의 값대로 변경됨.
WHERE문을 빠뜨리면 재앙이 일어날 수도 있으므로 조심해야 함!!!
UPDATE topic SET description='!!! oracle is... !!!', title='Oracle!' WHERE id=2;
13강. DELETE
검색: delete in mysql
WHERE문을 빠뜨리면 모든 행이 삭제되므로 큰일남. 아래와 코드 같은 작성할 때 topic 까지만 쓰고 엔터누르면 안됨.
DELETE FROM topic WHERE id = 5;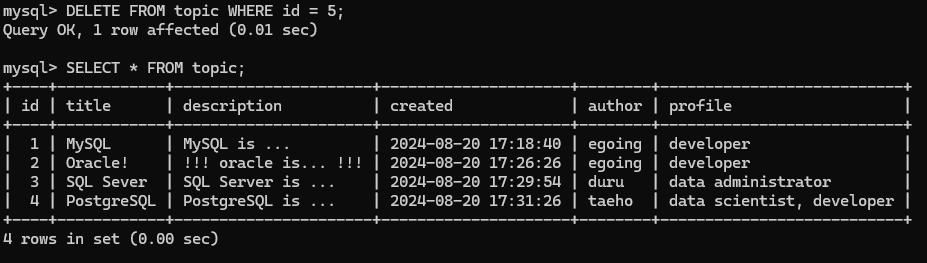
지금까지 배운 내용 정리:
테이블 만들기 : CREATE문 ( CREATE 테이블명() )
Create - INSERT문 ( INSERT INTO 테이블명() VALUES() )
Read - SELECT문 ( SELECT / SELECT FROM / SELECT FROM WHERE / SELECT FROM WHERE ORDER BY )
Update - UPDATE문 (UPDATE SET WHERE )
Delete - DELETE문( DELETE FROM WHERE )
14강. 수업의 정상
기술을 만나면 혁신(Innovation)과 본질(essence)로 분리해서 봄. 생각과 판단에 도움.
혁신 - Relational (관계형)
본질 - Database (CRUD)
15강. 관계형데이터베이스의 필요성
표에서 데이터가 중복되어 들어간 경우가 있음. 어떤 것을 봤을 때 데이터가 중복되고 있다면 이것은 무언가 개선할 것이 있다는 중요한 신호임. 중복되고 있는 데이터가 용량이 크고 굉장히 복잡하다면 그리고 이것이 천만번정도 반복된다면 경제적으로 기술적으로 손해임. 천만번 반복되고 있는데 그 데이터의 수정이 필요하다면 수정이 어려울 것. 그리고 각각의 데이터들이 용량이 크고 데이터가 많다면 서로가 같은 데이터임을 확신하기가 어려울 수 있고 혹은 동명이인이 여러명일 수 있음.
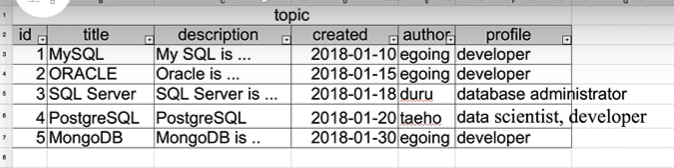
- 만약 'egoing'이라는 이름을 한국어로 '이고잉'이라고 바꾸려고 한다면 여러 개를 일일이 바꾸어야 함.

(위 두 사진은 강의 영상 중 캡처를 하였다. 출처: https://www.youtube.com/watch?v=-w1vJgslUG0&t=296s)
- 기존의 topic 테이블에서 저저들에 대한 정보를 별도의 테이블(author)로 만듦. 그리고 이 테이블에는 id값이 있고 이름과 프로필이 있음. 각각의 사람에게 id값을 줌.
- 기존의 topic 테이블에 존재하던 중복된 데이터들은 사라지고 각각의 데이터들에 대한 author 테이블의 식별자인 id값으로 대체됨.
- 만약에 author 테이블의 'egoing'이라는 이름을 한국어로 '이고잉'으로 바꾼다면 이 author 테이블을 참조하고 있는 모든 행에 데이터가 바뀌었다고 할 수 있음.
- 즉, 기존의 topic 테이블에서와 달리 author 테이블 하나만 수정하면 됨. 유지보수가 훨씬 편해짐.
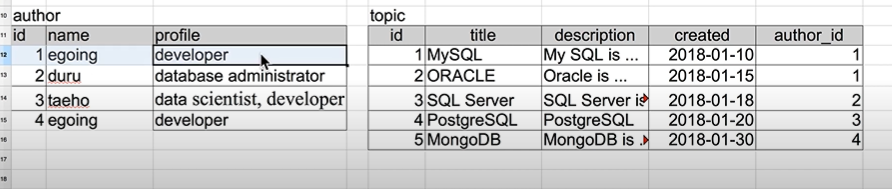
- 그리고 author_id값이 1이면 author 테이블의 id가 1번인 egoing이라는 사람임을 알 수 있음. 기존의 topic 테이블에서는 이름이 egoing인 경우가 여러 건인데 profile도 똑같다면 같은 사람인지 아니면 동명이인인지 알 수 없었음.
- 기존의 테이블과 달리, topic의 MySQL과 MongoDB에 대해 글을 쓴 저자가 서로 다른 egoing임을 알 수 있음.
하지만 장점이 생기면 단점이 생김. 트레이드 오프(trade-off)
기본의 테이블은 author와 profile이 하나의 표에 다 드러나기 때문에 직관적임. 하지만 테이블을 별도로 쪼개서 테이블의 참조값만을 적어놓게 되면 그 데이터를 볼 때 그 행에 해당하는 별도의 표를 열어서 비교해가면서 봐야하는 불편함이 있음.
하지만! MySQL과 함께라면 데이터를 별도의 테이블로 보관함으로써 중복을 발생시키지 않으면서도 실제로 데이터를 볼 때에는 하나의 표로 합쳐진 형태로 볼 수 있음. 저장은 분산해서 볼 때는 합쳐서. 아래와 같이 가능함.

16강. 테이블 분리하기
테이블을 보여주는 명령
SHOW TABLES;
기존의 topic 테이블은 이름을 topic_backup으로 변경
RENAME TABLE topic TO topic_backup;
topic_backup 테이블을 보고 topic테이블과 author 테이블을 생성. cmd에서 탭을 분할하여 표와 컬럼(필드)을 띄워놓고 INSERT 작업.
아래 명령으로 author 테이블의 필드를 볼 수 있음. DESC는 description을 줄인 것.
DESC author;
코드 복사 붙여넣기 : https://opentutorials.org/course/3161/19521
--
-- Table structure for table `author`
--
CREATE TABLE `author` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) NOT NULL,
`profile` varchar(200) DEFAULT NULL,
PRIMARY KEY (`id`)
);
--
-- Dumping data for table `author`
--
INSERT INTO `author` VALUES (1,'egoing','developer');
INSERT INTO `author` VALUES (2,'duru','database administrator');
INSERT INTO `author` VALUES (3,'taeho','data scientist, developer');
--
-- Table structure for table `topic`
--
CREATE TABLE `topic` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`title` varchar(30) NOT NULL,
`description` text,
`created` datetime NOT NULL,
`author_id` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
);
--
-- Dumping data for table `topic`
--
INSERT INTO `topic` VALUES (1,'MySQL','MySQL is...','2018-01-01 12:10:11',1);
INSERT INTO `topic` VALUES (2,'Oracle','Oracle is ...','2018-01-03 13:01:10',1);
INSERT INTO `topic` VALUES (3,'SQL Server','SQL Server is ...','2018-01-20 11:01:10',2);
INSERT INTO `topic` VALUES (4,'PostgreSQL','PostgreSQL is ...','2018-01-23 01:03:03',3);
INSERT INTO `topic` VALUES (5,'MongoDB','MongoDB is ...','2018-01-30 12:31:03',1);
17강. JOIN /관계형 데이터베이스의 꽃
JOIN을 이용해서 분리된 테이블을 읽을 때 하나의 테이블인것처럼 읽을 수 있음..
SELECT 보여줄 컬럼목록(필드목록) FROM 테이블명 LEFT JOIN 테이블명 ON 합칠 기준
author 테이블과 topic 테이블의 연결 고리는 author 테이블의 id와 topic 테이블의 author_id임. 이들이 같은 것을 이용해서 합치라는 것임. LEFT는 지금은 의미를 생각하지말고 그냥 쓸 것.
SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.id;
author_id와 id가 둘이 겹치는게 꼴보기 싫다면 SELECT 뒤에 *이 아니라 보고싶은 칼럼명을 적으면 됨. 단, id같은 경우 topic 테이블의 id인지 author테이블의 id인지 확실치 않아 오류가 생기므로 어느 테이블의 id인지 '테이블명.id'와 같은 형태로 명시해야 함. 또 보고싶은 칼럼들 중에서 표로 보여질 때 이름을 바꾸어서 보이고 싶다면 'AS 바꾼이름'을 그 칼럼 뒤에 작성해주면 됨.
SELECT topic.id AS topic_id, title, description, created, name, profile FROM topic LEFT JOIN author ON topic.author_id = author.id;
관계형 데이터 베이스
저자와 프로필 정보가 필요한 또 다른 댓글 테이블을 만들더라도 그 정보들을 일일이 댓글 테이블에 넣는 것이 아니라, id값을 통해서 식별자를 만들고 저자 테이블과 연결고리를 만들어 놓음. 만약 저자의 정보에 대해 수정사항이 있으면 댓글 테이블을 수정할 필요 없이 저자 테이블만 수정하면 됨.
18강. 인터넷과 데이터베이스
인터넷과 데이터베이스의 관계, 데이터베이스 서버의 의미

인터넷이 동작하기 위해서는 컴퓨터가 2대 필요함. 한대의 컴퓨터는 정보를 요청(클라이언트)하고 나머지 컴퓨터는 정보를 응답(서버)함. 웹 클라이언트(브라우저), 웹 서버, 게임 클라이언트, 게임 서버, 채팅 클라이언트, 채팅 서버 ...
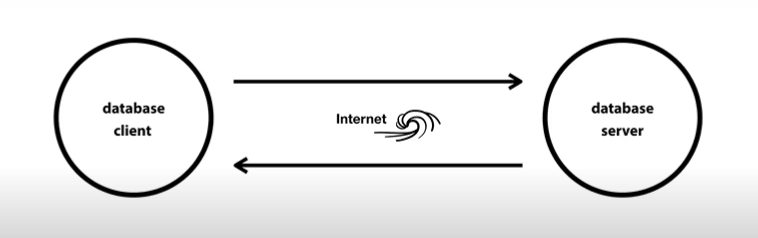
MySQL을 설치하면 MySQL은 두 개의 프로그램을 동시에 설치함. 하나는 데이터베이스 서버이고 하나는 데이터베이스 클라이언트임. 그리고 데이터베이스 서버에는 실제로 데이터가 저장되고 우리는 데이터베이스 클라이언트를 통해 데이터베이스 서버에 접속할 수 있음. 우리는 mysql -uroot -p를 통해 접속했는데 우리가 사용한 것은 mysql이라고 했을 때 실행되는 명령어 기반의 프로그램이었음. 실제로 mysql -uroot -p를 통해서 비밀번호를 입력하면 Welecome to the MySQL monitor라고 적힌 것을 볼 수 있음. 이 MySQL monitor는 데이터베이스 클라이언트 중 하나였던 것임. MySQL monitor는 MySQL을 설치하면 MySQL 서버에 접속할 수 있도록 기본적으로 번들로서 제공하는 것임. 또 명령어를 통해서 데이터베이스 서버를 제어하는 프로그램임.
MySQL Workbench 또한 데이터베이스 클라이언트로서 GUI환경(그래픽컬한 환경)에서 마치 엑셀을 다루듯이 데이터베이스를 다룰 수 있음.
전세계에 있는 수많은 데이터베이스 클라이언트들이 데이터베이스 서버를 중심으로 해서 데이터를 넣고 빼고 하는 것이 가능해짐. 웹이나 앱과 같은 UI를 사용하지 않고도 MySQL monitor나 Workbench와 같은 프로그램을 통해서 전세계에 있는 사람들이 하나의 데이터베이스서버를 이용해서 여러가지 정보를 주고받고 정보를 관리하는 것이 가능.
19강. MySQL Client
MySQL Client(클라이언트)
MySQL monitor : 명령어 기반(CLI 기반)의 프로그램
Workbench : GUI 기반의 프로그램(마우스로 조작가능)
많은 서버 컴퓨터들이 최대한 그 컴퓨터의 자원을 일 자체에 투여하기 위해서 GUI 기능을 제공하지 않는 경우가 많음. 그런 경우에는 MySQL Workbench를 그 컴퓨터 안에서는 실행할 수 없음. 하지만 MySQL monitor는 명령어 기반이기 때문에 어디서든 실행할 수 있다는 굉장히 중요한 장점 가짐.
명령어 기반(CLI 기반)의 프로그램과 GUI 기반의 프로그램(마우스로 조작가능), 이 둘의 장단점이 다름. 하는 일에 따라 맥락에 따라 이것도 쓰고 저것도 쓰고 장점만 취하는 것이 데이터베이스를 잘 사용하는 팁임.
검색: mysql client
20강. MySQL Workcbench
mysql : MySQL monitor를 사용하라는 뜻.
-u : 사용자
-p : 비밀번호를 입력하겠다는 뜻
-h : host의 약자. 인터넷에 연결되어 있는 각각의 컴퓨터가 host임. 지금 실행하는 MySQL monitor라는 클라이언트로 인터넷을 통해서 다른 컴퓨터에 있는 MySQL 서버에 접속하려고 하면 -h 뒤에 그 컴퓨터에 해당하는 주소를 입력하면 됨. 구글 직원이라면 -hgoogle.com, 페이스북 직원이라면 -facebook.com. 그런데 우리는 MySQL 클라이언트와 MySQL 서버가 같은 컴퓨터에 위치하고 있음. 이때에는 우리가 사용하고 있는 MySQL 클라이언트가 설치되어 있는 그 컴퓨터 자신을 가리키는 약속된 특수한 도메인인 localhost를 사용함. 그리고 localhost와 똑같은 의미의 주소가 있는데 127.0.0.1임.
만약 이 -h를 생략하면 암시적으로 MySQL monitor가 설치되어 있는 컴퓨터의 MySQL 서버를 가리키게 됨.
mysql -uroot -p -hlocalhost
Workbench 사용하기
+버튼 누르고 Connection Name은 my server로 Connection Method는 그대로 TCP/IP 사용. Hostname은 127.0.0.1로 MySQL Workbench가 설치된 컴퓨터의 MySQL 서버에 접속하겠다는 뜻임. localhost를 사용하면 오류가 발생할 수 있음. 그때에는 IP로 바꿔주면 됨. Port는 그대로 사용. Username은 root임. (앞서 사용했던 -uroot와 같은 것임) 비밀번호를 입력하면 저장됨. TestConnenction을 누르고 비밀번호를 입력하고 OK를 눌렀을 때 Successfully made ~ 라는 창이 뜨면 성공적으로 테스트가 된 것임. OK버튼을 누르고 접속을 하기 위해서 만들어진 my server를 누른다.
이전에 만들었던 opentutorials를 SCHEMAS(스키마) 목록에서 볼 수 있다. 데이터베이스를 대상으로 명령을 내리고 싶다면 데이터베스를 더블클릭하면 됨. opentutorials를 더블클릭하면 active schema changed to opentutorials라고 뜸. (강의의 workbench 버전과 다르다면 다를 수 있음. 나는 좌측의 Information 탭에서 Schema: opentutorials라고 뜸.)
Query라고 되어있는 부분에서 내리는 명령은 opentutorials라는 데이터베이스를 대상으로 명령을 내림. 명령을 입력하고 번개 모양 표시를 누르면 결과를 볼 수 있음.

스키마(데이터베이스)를 새롭게 만들고 싶다면 상단의 원통형아이콘을 선택(마우스를 올리면 Create a new schema in the connected server라고 뜸.) 이름을 입력하고 Apply를 누른 다음, SQL 명령으로 한번 이 과정을 보여주는 화면이 나오는데 한번 더 Apply를 누르면 만들어진다. MySQL monitor에서 명령(SHOW DATABASES;)을 통해 workbench라는 스키마(데이터베이스)가 잘 생성되었음을 확인할 수 있다.
스키마 목록에서 workbench를 눌러 active schema를 workbench로 바꾸어준다. 표를 만들고 싶으면 상단의 표 모양 아이콘을 누르면 된다. 마우스를 올리면 현재의 연결된 서버에서 active schema를 대상으로 해서 표를 만들어준다고 설명이 뜬다. 아래 사진과 같이 이름과 컬럼을 입력해준다. PK는 PrimaryKey, NN은 NotNull, AI는 Auto_Increment이다.

Apply 버튼을 누르면 아래와 같이 이 과정을 SQL문으로 나타낸 것을 보여준다. 한번더 Apply를 누르고 Finish를 누르면 테이블이 만들어진다.

이런것을 보면, MySQL Monitor를 쓰든 MySQL Workbench를 쓰든 모든 클라이언트들은 결국 SQL을 MySQL 서버에 전송함으로써 데이터베이스서버를 제어하게 됨.
좌측의 목록에서 아까만든 topic을 찾아 살짝 오른쪽으로 마우스를 옮기면 표아이콘이 뜨는데 이것을 클릭해서 볼 수 있다. 여기에 값을 입력하면 된다. 이후 Apply를 눌러 SQL문을 확인하고 다시 Apply하면 된다.
이외에도, 여러 기능이 있다. Schemas 탭을 Administration 탭으로 넘긴다.
데이터베이스가 사용자가 많은 경우에는 데이터베이스가 성능상의 영향을 받을 수 있다. PERFORMANCE의 Dashboard를 누르면 CPU 점유율, 메모리가 얼마나 남아있는지. 네트워크를 얼마나 쓰고 있는지를 보여주는 기능을 한다.
INSTANCE의 Startup / Shutdown을 데이터베이스 서버를 켜거나 끄는 기능을 가지고 있음.
그리고 데이터베이스의 데이터를 백업하거나 다른 서버로 이전할 때 Data Export를 사용할 수 있다.
세상에는 많은 MySQL 클라이언트가 있다.
그리고 MySQL 서버를 사용하고 있는 모든 웹 애플리케이션과 모든 앱, 모든 데이터분석하는 시스템들은 본질적으로는 모두가 MySQL 클라이언트이다.
21강. 수업을 마치며
Index
데이터가 많아지면 정리정돈을 하는 것이 중요함. 데이터가 많아지면 찾기가 어려움. (만약 서점에서 책을 정리정돈 없이 꽂으면 찾기 매우 어려울 것.)
데이터베이스의 index(색인) 기능을 이용해서 사용자들이 검색을 자주하는 컬럼에다가 색인을 걸어둠. 우리의 topic 테이블에서는 description이 됨. 거기에 색인을 걸어두게 되면 데이터가 들어올 때 데이터베이스가 그 컬럼의 정보를 잘 정리정돈함. 예를 들어 MySQL이라는 텍스트는 어떠어떠한 행에 저장되어 있고, ORACLE은 어디어디에 저장되어 있다 것을 별도로 정리해 놓음. 나중에 누군가가 MySQL을 검색하면 굉장히 빠른 속도로 그 데이터를 보여줄 수 있음. 미리 뒤져놓은 것이기 때문임. 데이터가 많아져 성능 상에 문제가 생기면 index라는 키워드를 찾아서 잘 적용할 것.
Modeling
또 데이터가 많아지면서 여러가지 문제가 생길 수 있음. 현실에서는 다양한 측면의 데이터들이 있기 때문에 데이터베이스의 구조(테이블)를 잘못설계하면 나중에 큰 낭패를 볼 수 있음. 그래서 어떻게 하면 데이터를 효율적으로, 중복이 없이, 더 좋은 성능으로 다룰지에 대해 정규화, 비정규화, 역정규화 ...등의 방법이 있음. 나중에 데이터가 많아져서 테이블을 어떻게 만들어야 할지 고민이 된다면 Modeling(모델링)이라는 키워드를 찾아서 공부할 것.
Backup
하드디스크에 대해 예측할 수 없는 것 - 언제 고장이 날지, 예측할 수 있는 것 - 반드시 고장이 난다. 자신의 노트북에 데이터를 저장을 해놓았는데 자기 것이 아닌 데이터까지 저장을 해놓는다는 것은 엔지니어로서 자격이 없는 것임. 누군가에게는 생명과 같은 정보일 수 있기 때문임. Backup의 기본적인 원리는 데이터를 복제해서 보관하는 것임. 내 컴퓨터와 별도의 컴퓨터에 데이터를 복제해서 보관한다면 데이터를 동시에 잃을 가능성은 현저히 낮아짐. 그리고 그 컴퓨터가 독립된 건물에 떨어져 있다면 훨씬 더 유실될 가능성이 낮아짐. 또 그 건물들이 서로 다른 국가, 대륙, 행성에 있으면 더 안전해짐. (다른 행성에 데이터백업센터?) 나중에 백업이 필요할 때 mysqldump(마이에스큐엘덤프), binary log(바이너리 로그)와 같은 키워드를 찾아 공부할 것.
Cloud
클라우드는 내 컴퓨터를 데이터베이스 서버로 쓰는 것이 아니고 아마존, 구글, 마이크로소프트, 네이버 등과 같은 대기업이 운영하고 있는 인프라 위에 있는 컴퓨터를 임대해서 사용하는 것이 클라우드 컴퓨팅임. 컴퓨터가 나에게 있지 않고 그 회사들의 데이터센터에 있고 우리는 그 컴퓨터를 눈으로 볼 수 없음. 그래서 원격제어를 통해서 다루게 됨. 특히 최근에는 클라우드 컴퓨팅 시스템이 고도화 되면서 MySQL 같은 데이터베이스 자체를 서비스화 시킴. 그 회사의 웹사이트에 들어가서 클릭 몇번하면 1분만에 데이터베이스서버가 만들어짐. 우리는 자신의 데이터베이스 클라이언트에 그 회사 서버의 고유한 주소를 입력해서 접속해서 사용할 수 있게 됨. 장점은 필요할 때 켜고 필요없을 때 끄면 더 이상 과금되지 않는다는 것임. 그리고 그 회사의 뛰어난 실력자가 사고가 일어나지 않도록 관리하고 있음. 그렇기 때문에 클라우드 서비스를 이용해서 데이터를 보관하면 데이터베이스가 가지고 있는 기능 자체에만 집중할 수 있다. 특히 백업적인 부분은 알아서 해주기 때문에 정말 쉬워짐. (강의가 업로드된 2018년도 기준) AWS(아마존) RDS, Google Cloud SQL for MySQL, AZURE Database for MySQL ... 등의 여러 클라우드 서비스들이 있음. 자신에게 맞는 조건의 서비스를 찾아 이용하면 됨.
Programming
데이터베이스 자체를 쓰는 경우는 적음. 데이터베이스 시스템을 일종의 부품으로 해서 이 부품을 기반으로 여러 완제품이 만들어짐. 우리가 사용하는 수많은 웹사이트, 앱, 분석결과 안에 뚜껑을 열어보면 MySQL이, 데이터베이스가 들어가 있음.
데이터베이스가 가진 아주 탁월한 정보 관리 기능을 활용해서 자신의 웹사이트, 애플리케이션, 데이터 분석을 하고 싶다면 컴퓨터 프로그래밍 언어를 배워서 데이터베이스 서버에 SQL을 던져줄 수 있는 방법들을 배우면 됨. 이것을 위한 검색 키워드는 Python mysql api, PHP mysql api, Java mysql api ...등이 있음. 자신이 사용하는 언어 뒤에 mysql api라고 검색하면 그 언어로 그 데이터베이스 시스템을 쉽게 핸들링 할 수 있는 여러가지 조작 장치를 찾을 수 있음.
'학습 > 데이터베이스' 카테고리의 다른 글
| (생활코딩) 데이터베이스1 정리 (0) | 2024.07.25 |
|---|